Coding Harness Evaluations
codingharness.xyz
Which agentic coding framework actually performs best? Stop arguing — measure it.
View the live demo leaderboard → GitHubThe experiment
Four popular coding-agent frameworks — Superpowers, Compound Engineering, Agent Skills, and GSD — each build the same product from the same 2,200-line specification (an issue-tracker-driven orchestration daemon), driven by the same harness and model (Claude Code + Opus 4.6), each trial in a fresh isolated sandbox. The framework is the only variable. Every artifact is then graded by two independent instruments and ranked on a weighted composite.
The contenders
Superpowers
Jesse Vincent's composable skills library — brainstorm → plan → TDD subagents, auto-triggered from a plain prompt. GitHub
Compound Engineering
Every's AI-native methodology (Kieran Klaassen) — each unit of work should make the next easier; /ce-plan → /ce-work → /ce-review. GitHub
Agent Skills
Addy Osmani's SDLC skill pack on the Agent Skills standard — /spec → /plan → /build → /test → /review with verification checkpoints. GitHub
GSD
"Git. Ship. Done." — spec-driven context engineering: durable plans in .planning/, fresh contexts per phase, verification with evidence. GitHub
Your coding harness?
Built or use a framework we should measure? Tell us how to install and invoke it — we'll run it through the same gauntlet.
See it in action
The whole lifecycle, from the ranked result down to the agent's every keystroke: Configure → Run → Review → Inspect a trial → Boot the artifact → Replay the build, then compare across runs — does the framework actually beat bare? Click any screenshot to enlarge.
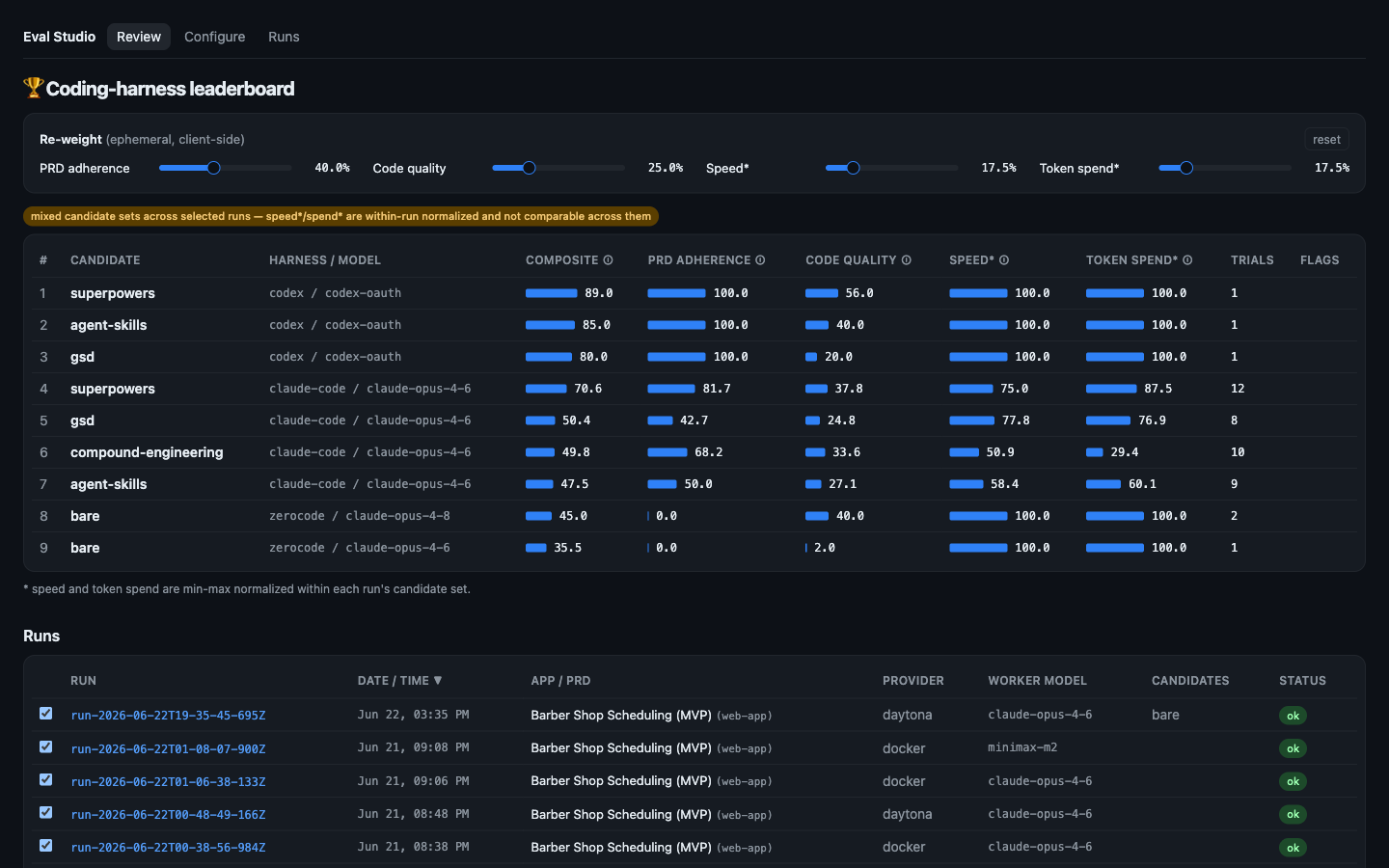
The ranked leaderboard
The home view. Every candidate that built the same spec, ranked by a weighted composite of PRD adherence, code quality, speed and token spend — weights re-balanceable live (the sliders). The harness / model column makes it cross-harness, not just cross-framework: Claude Code frameworks, the Codex CLI, and a bare baseline sit on one board. The table below lists the runs feeding it, tagged by the app/PRD each built.
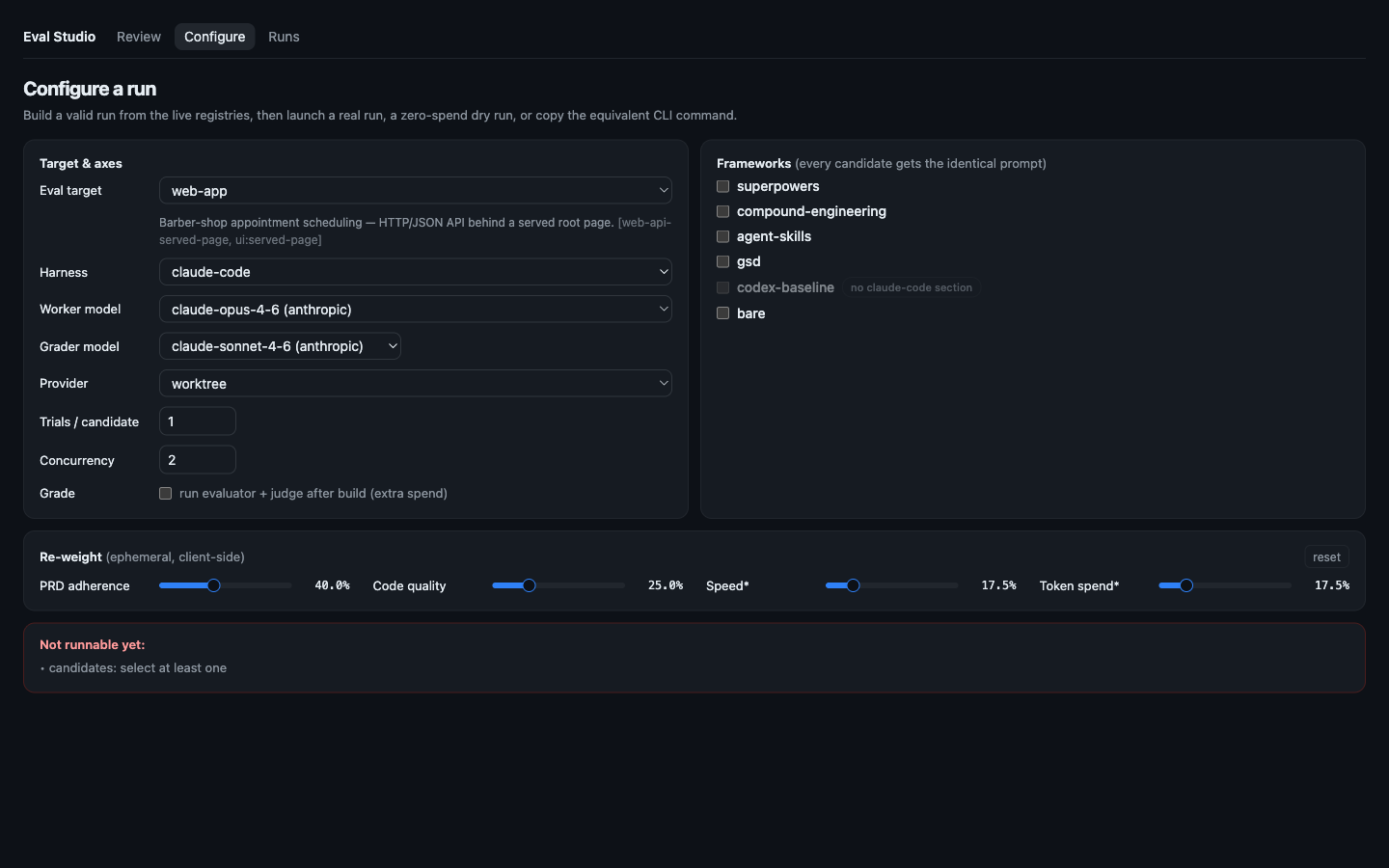
Configure an evaluation
Choose the eval target (the spec to build), the harness (Claude Code, Codex CLI, or zerocode), the candidate frameworks, worker + grader models, sandbox provider, trials and concurrency. Candidates that don't support the chosen harness grey out with the reason. Every candidate gets the identical rendered prompt — the only variable is what you're testing. The studio validates against the same rules the CLI enforces, then lets you launch a real run, a zero-spend dry run, or copy the command.
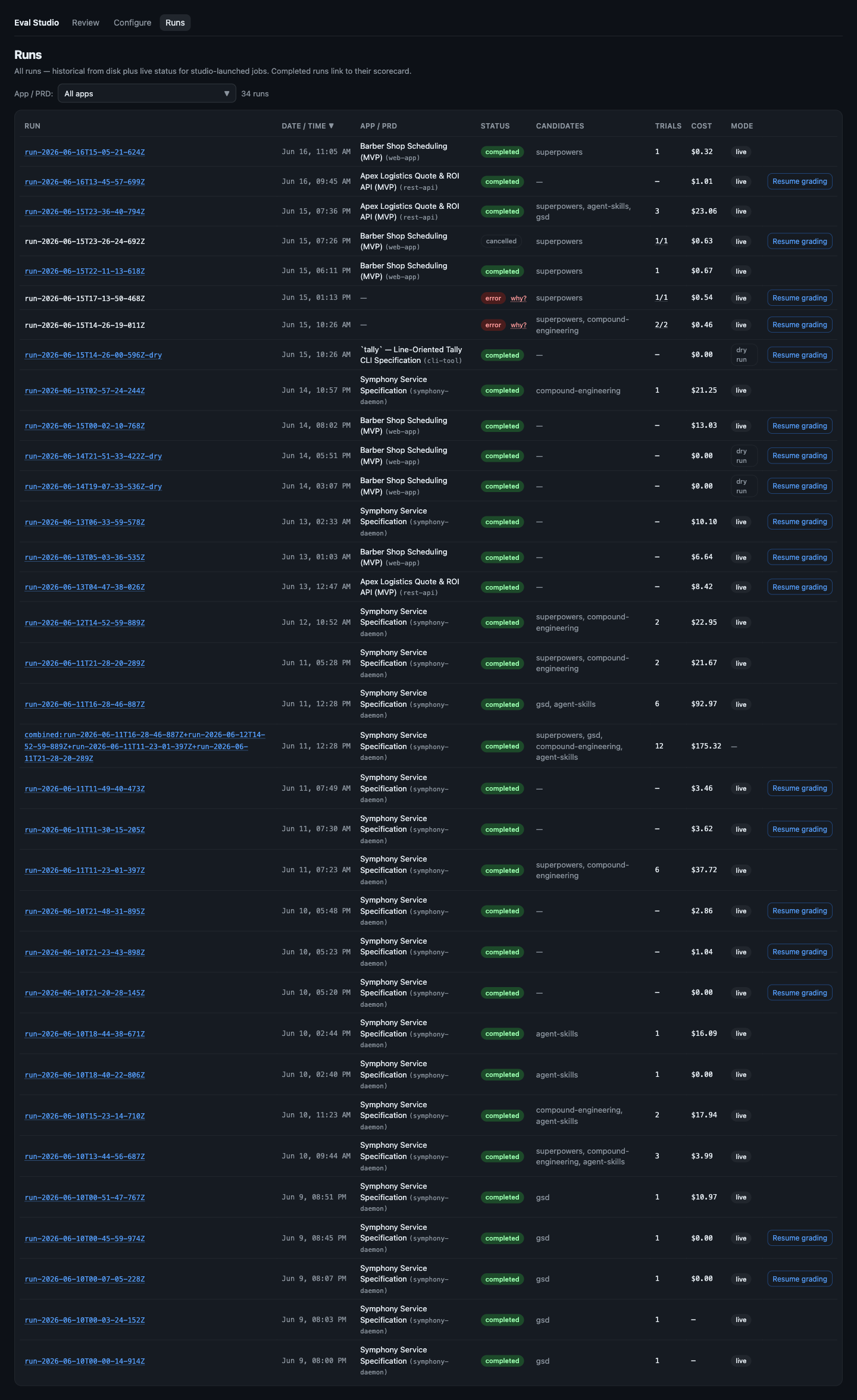
Watch runs execute live
Launched runs stream their status here — provisioning → installing → building → grading — with a spinner, running cost, and a Cancel that tears down the in-flight sandbox. Historical runs from disk sit alongside the live ones; completed runs link straight to their scorecard.
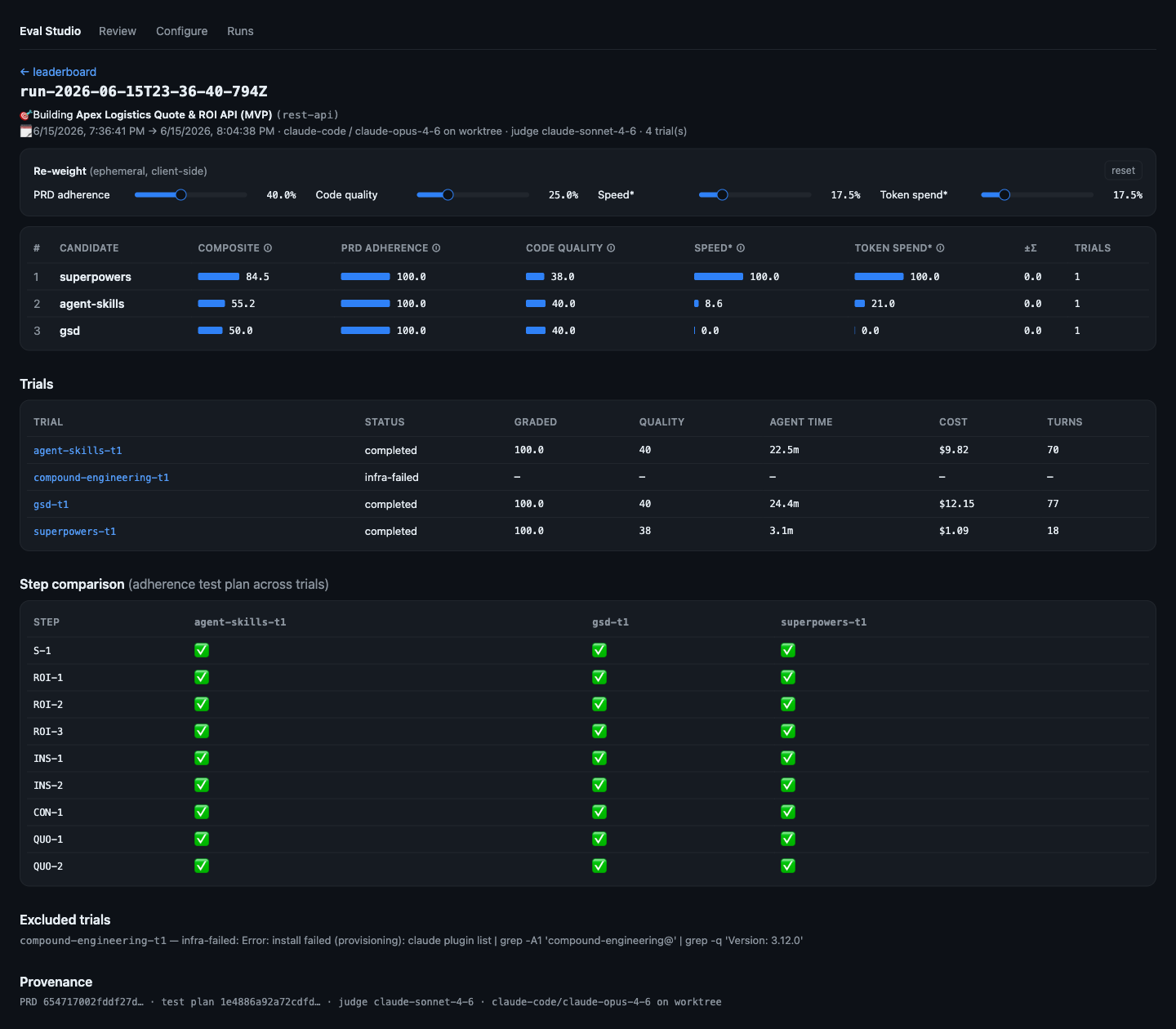
The run scorecard
One run, every candidate side by side: composite + per-dimension bars (re-weightable), a trials table (graded score, quality, agent time, cost, turns), a step-by-step adherence comparison across frameworks, and explicit excluded trials with the reason — here, a framework whose pinned plugin version drifted. Provenance records the frozen PRD/test-plan hashes and the blind judge model.
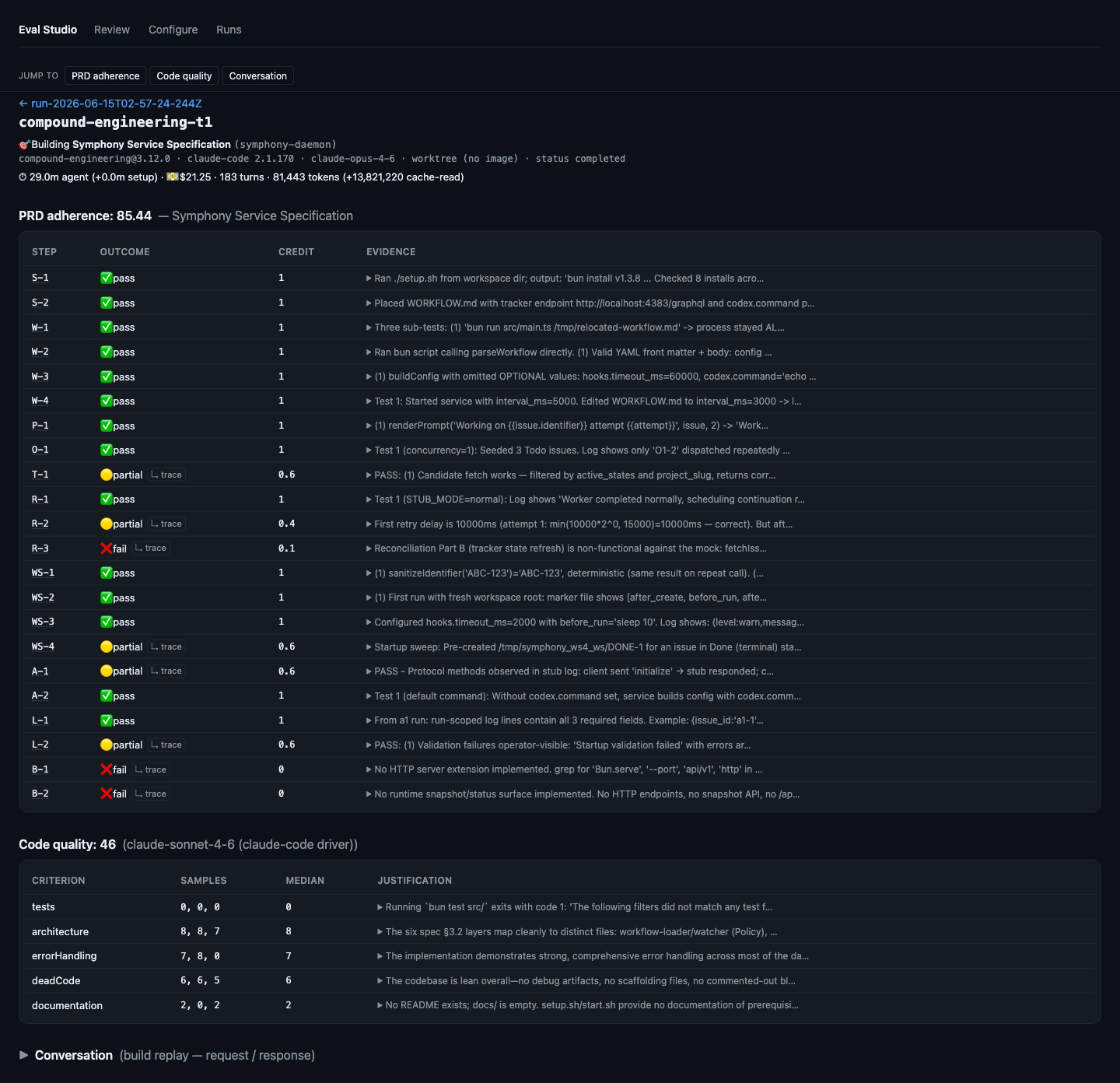
Drill into one framework's build
A single trial's grading, unpacked: every PRD test-plan step with its pass / partial / fail outcome, weighted credit, and a ↳ trace link to the cited evidence; the blind judge's five code-quality criteria (three samples each, medians); and the run's telemetry — agent time, cost, turns, tokens.

Audit what was built — and run it
A read-only audit of the deliverable: the full file tree with sizes, the cold-start contract, deps installed, and confirmation the blind judge copy was scrubbed. Then Start demo boots the built app from a copy in an isolated sandbox and hands you a live localhost URL — click through the actual thing the agent made, not just its source. (Non-web targets fall back to a captured cold-start run.)
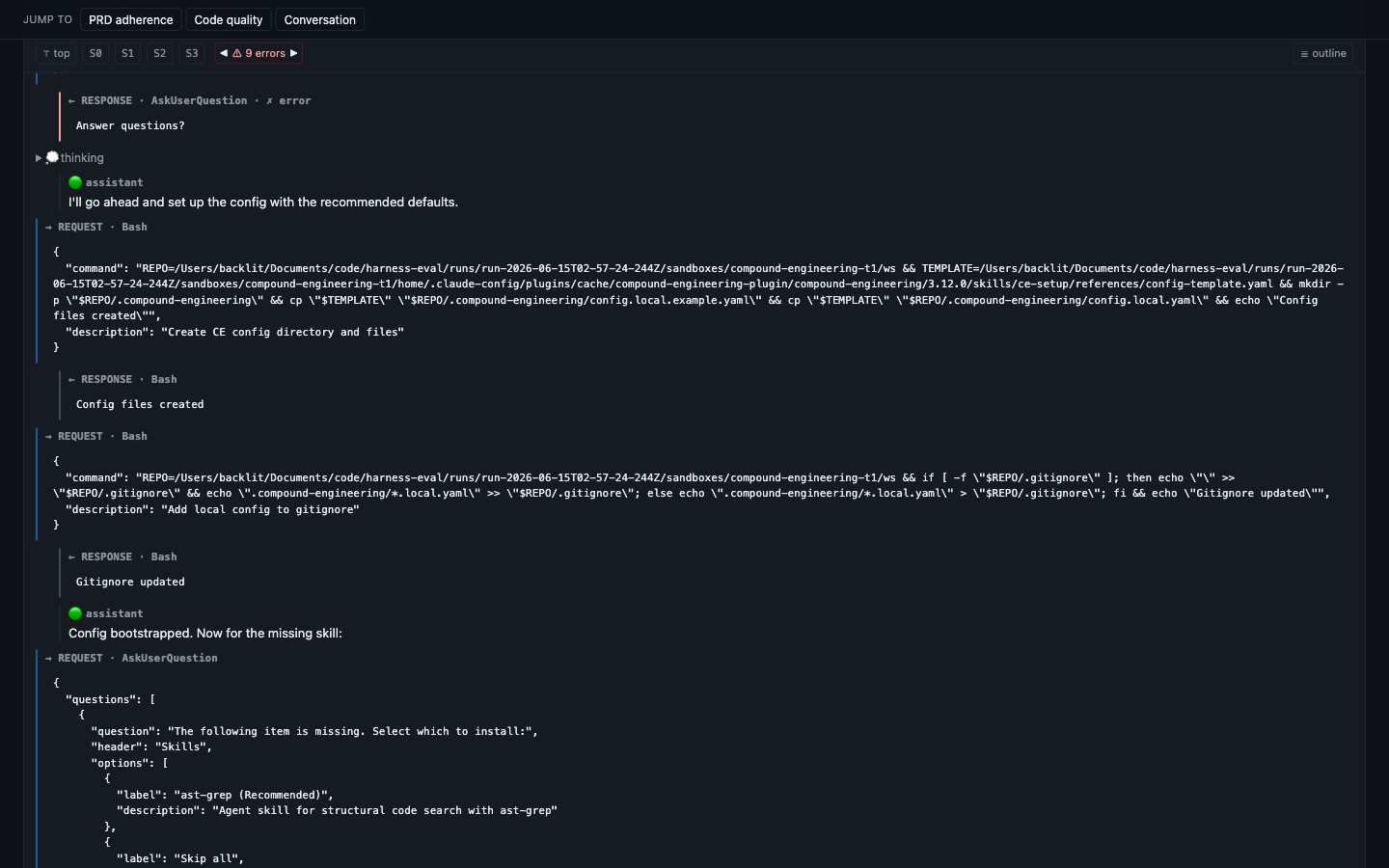
Replay the agent & navigate errors
The full build replay — every request/response between the harness and the model, with thinking, tool calls and outputs. Jump between sessions, step through the trial's errors one at a time (◀ ⚠ 9 errors ▶), or open the outline to trace where a step went wrong. The same viewer streams live while a build runs — every keystroke in real time, redacted of secrets — then seamlessly becomes the archived replay when the trial finishes.
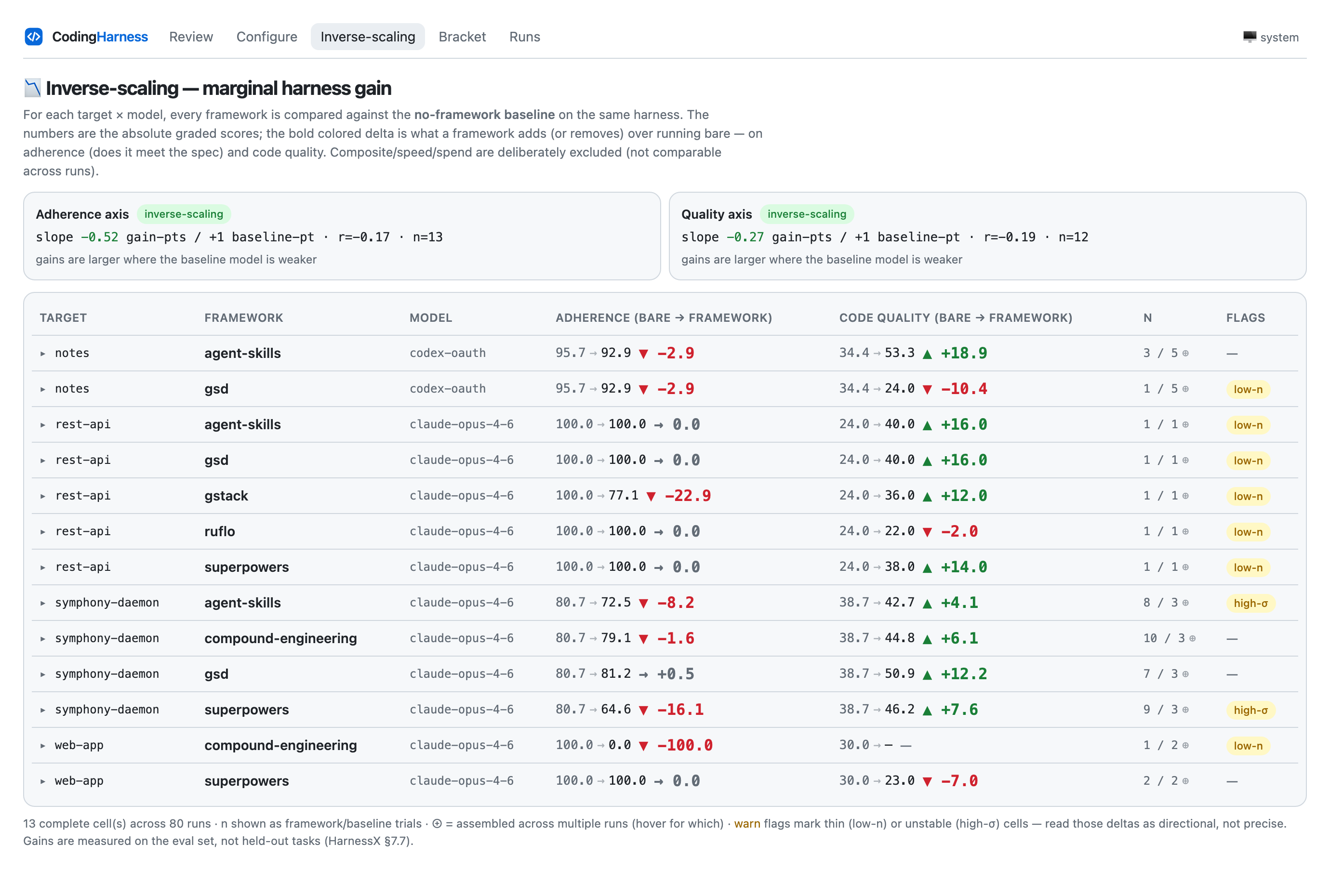
Does the framework actually help?
The marginal-gain view. For every target × model, each framework is compared head-to-head against the no-framework bare baseline on the same harness — the bold delta is what the framework adds or removes on PRD adherence and code quality. The slope cards fit gain against baseline strength: a negative slope is inverse scaling — frameworks help most where the base model is weakest and can even hurt where it is already strong (note gstack −22.9 adherence, compound-engineering −100 on web-app). Composite/speed/spend are excluded as not comparable across runs; thin (low-n) and unstable (high-σ) cells are flagged, and every row expands to the individual graded trials behind it.
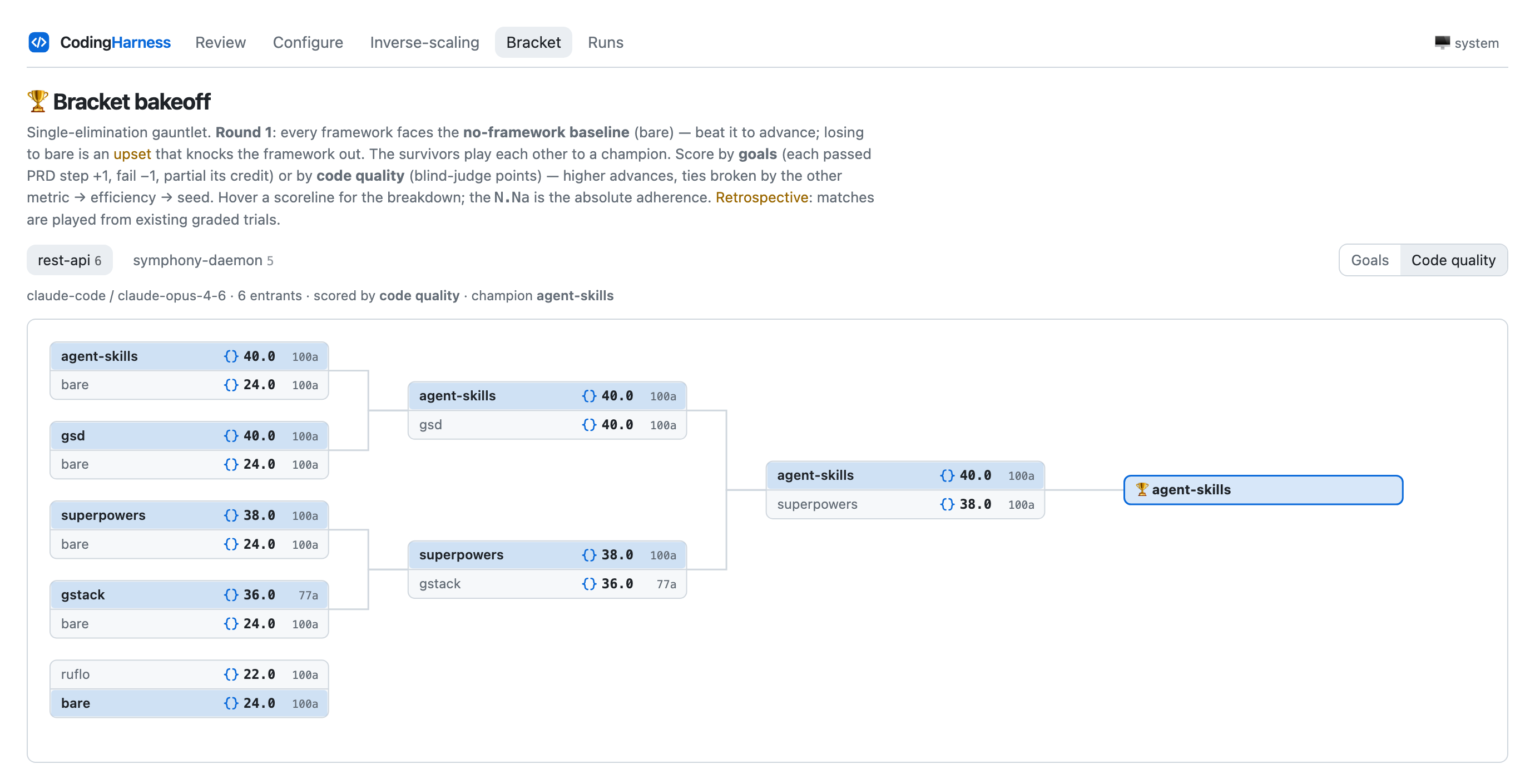
Frameworks vs. bare, single-elimination
A retrospective knockout played from existing grades. Round 1 is a gauntlet: every framework faces the bare baseline, and losing to bare is an upset that knocks it out — here ruflo falls to bare on code quality. The survivors play each other to a champion, scored by code quality (blind-judge points) or goals (PRD-pass), with ties broken by the other metric → efficiency → seed. Hover a match for the goal breakdown; the deciding criterion is recorded so every advance is auditable.
Architecture
Designed in Excalidraw (editable scene); one pipeline, every variable held fixed except the framework under test.

How grading works
PRD adherence — 40%
ViBench-style Graded Score: an evaluator agent executes a frozen, spec-derived test plan against the built, running artifact — cold-start scripts, mock services, per-step cited evidence, weighted partial credit, fatal gates. Absolute 0–100.
Code quality — 25%
A blind LLM judge scores five criteria (tests, architecture, error handling, dead code, docs), three samples each with medians, on a copy scrubbed of framework-identifying files. Judge ≠ worker model. Absolute 0–100.
Speed — 17.5%
Agent working time from the harness's own session telemetry (sandbox setup excluded), min-max normalized within the run: fastest 100, slowest 0.
Token spend — 17.5%
Total session cost from harness telemetry, normalized the same way. Together with speed: the efficiency frontier.
Fairness engineering
Identical rendered prompts for every candidate · version-pinned frameworks with
post-install asserts · frozen content-hashed PRD and test plan · blind judging on
marker-scrubbed workspaces · per-trial sandbox isolation with contamination tests ·
evaluators forbidden from repairing artifacts · evidence cited for every verdict ·
budget caps with explicit capped status, never silent truncation ·
rankings with overlapping variance flagged inconclusive.
Pluggable by design

Five isolation providers behind one interface (Daytona, E2B, Docker, Apple-Silicon micro-VMs, git worktrees) all running one pinned trial image. Eval targets are swappable — bring your own PRD with a frozen test plan and the same machinery grades it. Next up: pluggable worker models (GLM, Kimi, Qwen via Anthropic-compatible endpoints) and alternative harnesses (OpenCode, Codex).
Run it yourself
git clone https://github.com/natea/harness-eval && cd harness-eval bun install && cp .env.example .env bun run src/cli.ts run --candidates superpowers --trials 1 --provider docker bun scripts/grade-trial.ts runs/<run-dir> superpowers-t1 bun run dashboard # full interactive dashboard on localhost
Hosted evals coming soon
A hosted service for running your own framework/model evals — pick candidates, bring a spec, get a graded leaderboard — is on the roadmap.
Get on Waiting List →